3D Object-Detection for Autonomous Driving
3D Bounding box on KITTI dataset images | Jan-March 2023.

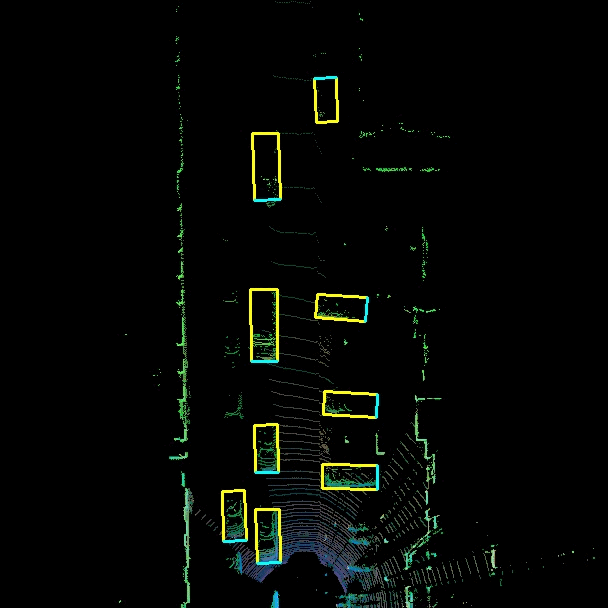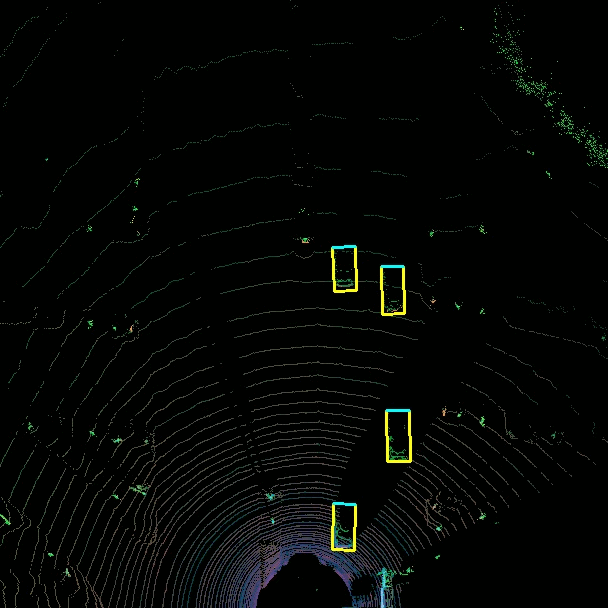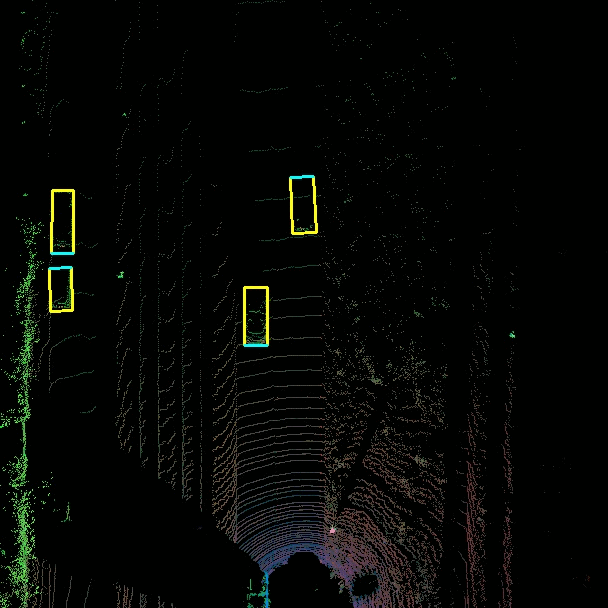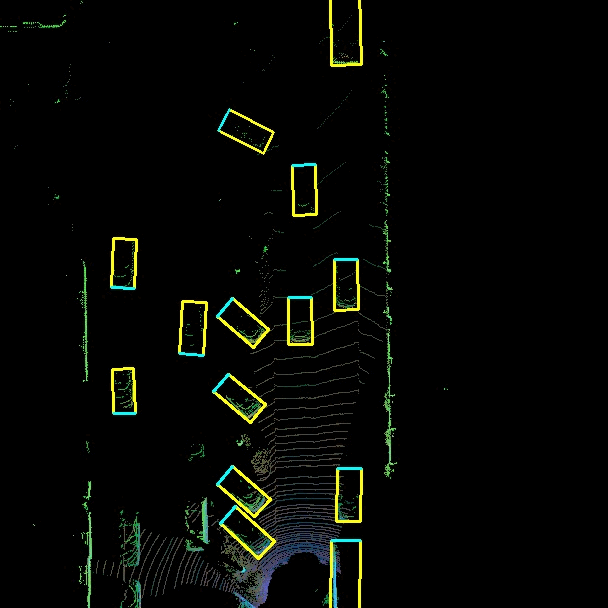
Overview
The goal of the 3D object detection is to obtain the 3D location, size and orientation of the detected object. This is particularly useful for autonomous driving where accurate knowledge of the 3D environmentment is essential to make navigation decisions. Sensor fusion is incorporated in this project where data from both the velodyne Lidar sensor and camera is used. While cameras offer rich visual information that can be utilized for object recognition and classification, LIDAR delivers precise depth information about the surroundings.
Description
Complex YOLO model specifically YOLO-v3 is implemented.

Training
During training, the Complex-YOLO model is trained to predict the class labels and bounding boxes for the objects in the input images, using the ground truth labels provided in the KITTI dataset. The model is optimized to minimize the difference between its predictions and the ground truth labels.
Input -> 2D camera RGB images + sequence of 2D LIDAR point clouds (to get depth information) (Bird’s eye view representation of the Lidar point cloud). Neural Network -> training Output -> 3D bounding boxes indicating the location, orientation, and size of the detection object.
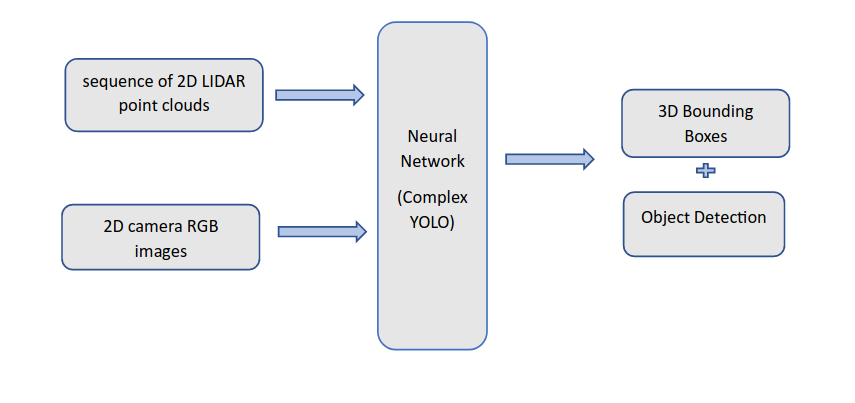
Inference
During inference, the model is applied to new images, and it generates predictions for the class labels and bounding boxes of the objects in the images. In addition, the model applies post-processing step of non-maximum suppression to the predicted bounding boxes, to remove overlapping bounding boxes and improve the final output.
Input -> LIDAR point clouds processed to get 3D feature maps. Camera images processed to get 2D feature maps.
Neural Network -> These feature maps fed into neural network to estimate 3D point space in LIDAR coordinate system.
Output -> Object detection -> Class + 2D detection.
3D bounding box -> 3D box in LIDAR point cloud coordinate system.
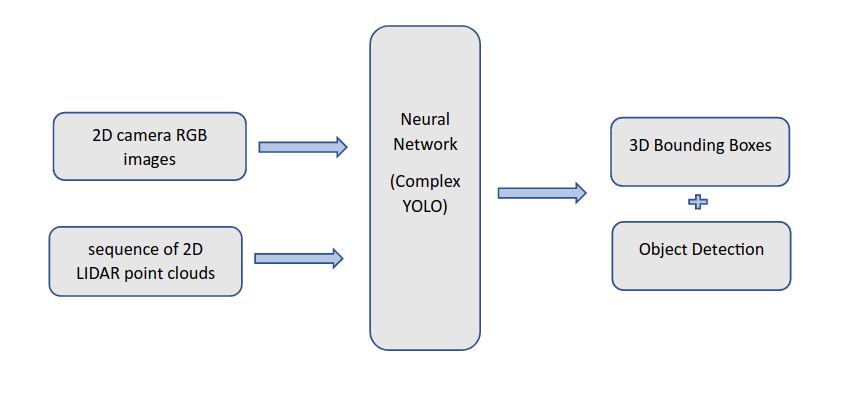
Evaluation
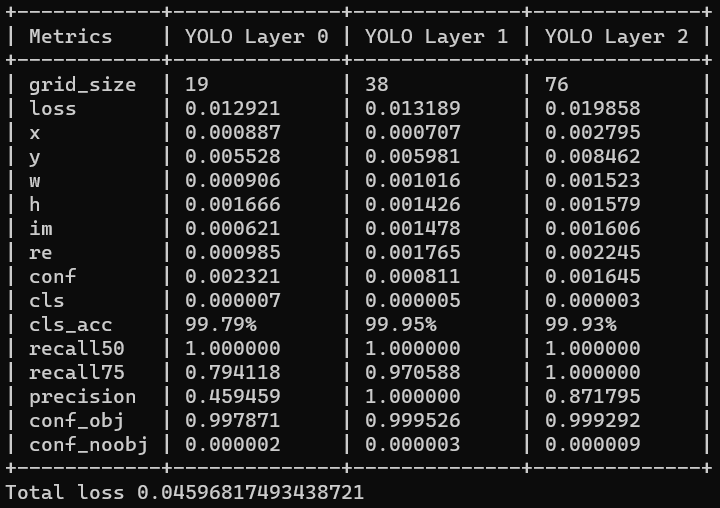
The weights obtained after training the model for 115 epochs has:
A total loss = 0.0459 approx
classification accuracy = 99.79% approx
Summary
Obtaining 2D and 3D feature maps (sensor fusion) occurs during inference. (i.e. after training neural network and then it is applied to new data to detect and localize objects in that scene.
During Training -> Labelled data; Lidar point cloud + camera image data + ground truth annotation (object location, orientation, size). Weights and biases adjusted to minimize differences between predicted output and ground truth annotation.
During Inference -> Lidar point cloud + camera image data. Sensor fusion to generate 2D and 3D feature maps. These feature maps are fed into network for object detection and localization. Output of network used to predict location, orientation, and size.
Github
References
https://doi.org/10.48550/arXiv.2004.10934